| 全文四个小节:1)连接主义的胜利、2)语言模型的进化、3)人类的智能助理 4)GPT-4 翻译 人类监制,本文将带领大家快速了解机器是如何进化到能理解世界的!一共 5000 字左右,预计阅读时间 15 - 20 分钟。 就在我为《GPT 时代人类再腾飞》写下译者序的前几天,“AI 教父”杰弗里·欣顿(Geoffrey Hinton)教授刚刚宣布从谷歌离职。75岁的他在接受《纽约时报》专访时表达了年龄只是他离开的部分原因,另一个重要原因是AI已经发展到了需要谨慎对待的关键时刻,他需要从行业奠基人转变成行业监督者的角色,来提醒大家如何面对AI监管的挑战。 我们正处在一个什么样的历史时刻?欣顿教授把 ChatGPT 的出现比作第二次工业革命中电的发明,再往前一点就是人类第一次发明了轮子,这两次变革都极大地释放了生产力。现在,我们正处于信息革命中互联网发明后最重要的时刻。 欣顿教授这次面对媒体表现出来的对智能变革的态度,表明他是个十足的保守派,以防止 AI 毁灭人类为己任。每当变革性新技术出现的时候,乐观和悲观的对立都会非常突出,这次也不例外。本书的作者里德·霍夫曼(Reid Hoffman)则显得十分乐观,要让AI来帮助人类提升人性和扩展能力,这也许和他是领英创始人和 OpenAI 早期投资人有关。通常,企业家和风险投资人都是新技术的乐观主义者,而学者大多会在冷静思考中保持谨慎。 在大家正式阅读本书之前,我先来补充一些霍夫曼没在书中提及的有关这次智能革命的背景知识。 连接主义的胜利
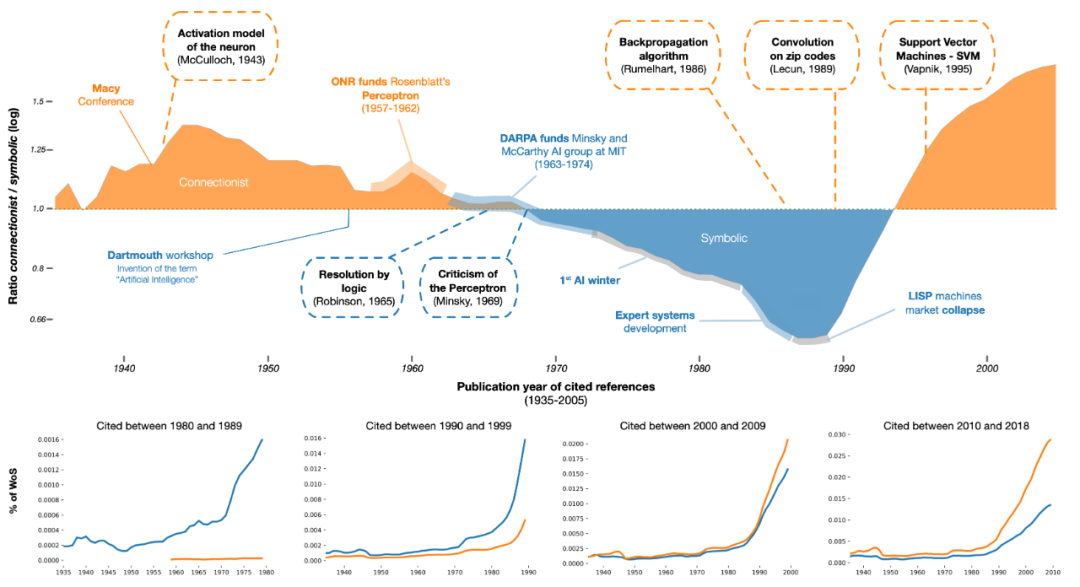
神经元的复仇 - Neurons spike back 在最初的 20 多年里,因为感知器模型(Perceptron Model)的发明,仿生学派一直是 AI 研究的主要方向,但受制于当时的算力和神经网络的算法,在计算机编程语言的快速进化的压力之下,用程序逻辑来实现机器智能的“符号主义”开始大行其道。只有以约翰·霍普菲尔德(John Hopfield )为代表的少数研究人员还在为“连接主义”的理想而奋斗,欣顿教授就是其中之一。 采访中欣顿教授透露因为不愿意接受五角大楼的资助,在上世纪八十年代, 他辞去了卡内基梅隆大学计算机科学教授的工作,只身前往加拿大多伦多大学,继续从事神经网络的研究。欣顿教授对人工智能领域最大的贡献就是一种叫做反向传播(Backpropagation)的算法,这是他与两位同事在八十年代中期首次提出的,这项技术让人工的神经网络实现了“学习”,如今它几乎是所有机器学习模型的基石。简而言之,这是一种反复调整人工神经元之间连接权重的方法,直到神经网络产生能达到预期的输出。 采访中,欣顿教授透露,因为不愿意接受五角大楼的资助,在 20 世纪 80 年代,他辞去了卡内基梅隆大学计算机科学教授的工作,只身前往加拿大多伦多大学,继续从事神经网络的研究。欣顿教授对AI领域最大的贡献是一种叫作反向传播(Backpropagation)的算法,这是他与两位同事在20 世纪 80 年代中期首次提出的,这项技术让人工的神经网络实现了“学习”,如今它几乎是所有机器学习模型的基石。简而言之,这是一种反复调整人工神经元之间连接权重的方法,直到神经网络产生能达到预期的输出。 连接主义的全面逆袭从 2012 年开始,那年欣顿教授和他在多伦多大学的两名学生伊尔亚·苏茨克维(Ilya Sutskever)和亚历克斯·克里切夫斯基(Alex Krishevsky)建立了一个神经网络 —— AlexNet,可以分析成千上万张照片,并教会人们识别常见的物体,如花、狗和汽车。使用反向传播算法训练的卷积神经网络(Convolution Neural Networks,CNN)在图像识别方面击败了当时最先进的逻辑程序,几乎使以前的错误率降低了一半。 从 2012 年到现在,深度神经网络的使用呈爆炸式增长,进展惊人。现在机器学习领域的大部分研究都集中在深度学习方面,人类第一次开启了AI的潘多拉魔盒! 语言模型的进化
2017 年谷歌大脑(Google Brain)和多伦多大学的研究人员一同发表了一篇名为“Attention Is All You Need”(暂译《注意力就是你所需要的》)的论文,里面提到了一个自然语言处理模型—— Transformer,这应该是继欣顿教授的 AlexNet 之后,深度学习领域最重大的发明。2018 年,谷歌在Transformer的基础上实现了第一款开源自然语言处理模型 BERT。 欣顿教授的高徒伊尔亚·苏茨克维在2015年离开谷歌后参与创办了 OpenAI,作为首席科学家,他很快意识到了 Transformer 的统一性和可工程化的价值,这个来自谷歌的研究成果很快被 OpenAI采用。就在 GPT-4 发布后的一周,伊尔亚·苏茨克维与英伟达首席执行官黄仁勋在 GTC(GPU Technology Conference)活动上有一个对谈——“AI Today and Vision of the future”(暂译“人工智能的今天和未来愿景”)。其中伊尔亚·苏茨克维提到,他坚信两件事情,第一就是模型的架构,只要足够深,到了一定的深度,“Bigness is the Betterness”,简单来说就是大力出奇迹,算力加数据,越大越好,这也是为什么 Transformer 的模型架构要比他们之前使用的长短时记忆(LSTM)的架构要适合扩展;第二就是任何范式都需要一个引擎,这个引擎能够不断被改进和产生价值,如果说内燃机是工业革命范式的动力引擎,现在这个引擎就是 Transformer,GPT 也就是预训练(Pre-trained)之后的 Transformer。 伊尔亚·苏茨克维还有一个信念:“如果你能够高效地压缩信息,你就已经得到了知识,不然你没法压缩信息”。所以你想高效压缩信息,你就一定得有一些知识,所以他坚信 GPT-3 以及最新的GPT-4 已经有了一个世界模型在里面,虽然它们做的事情是预测下一个单词,但它已经表达了世界的信息,而且它能够持续地提高能力!就连强烈坚持世界模型理论的图灵奖获得者杨立昆教授(Yann LeCun),也对 GPT-4 的这种认知和推理能力感到惊讶,在尝试接受伊尔亚·苏茨克维的这个信念。
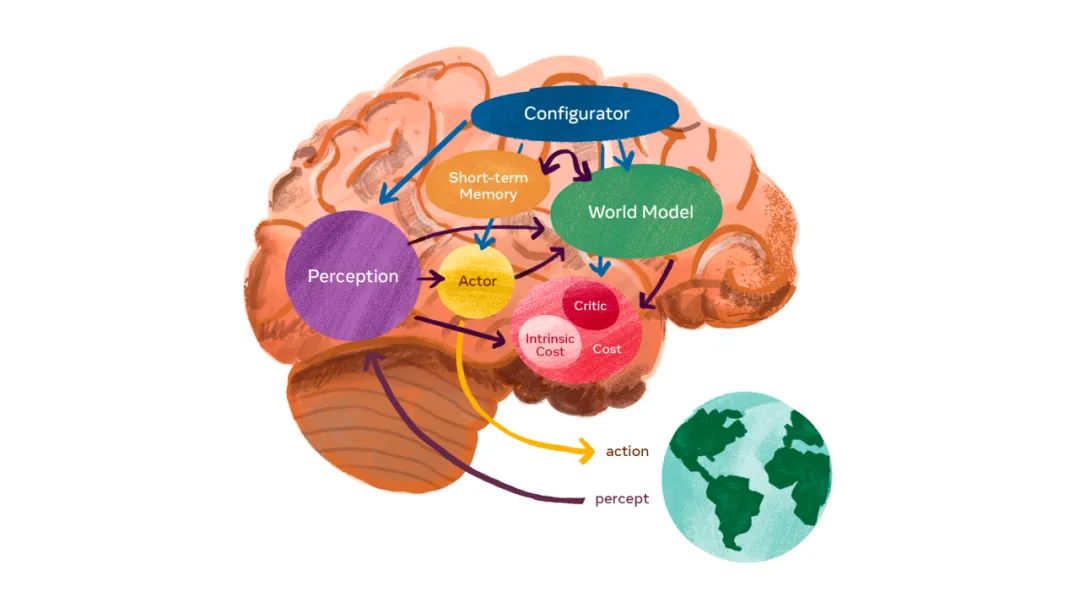
理解世界的模型 - LeCun’s World Model 加拿大计算机科学家里奇·萨顿(Rich Sutton)在他那篇著名的《惨痛的教训》(The Bitter Lesson)中提到,从 20 世纪 70 年代以来的 AI 研究中可以得到的最大教训是,利用计算的一般方法最终是最有效的,而且具有很大的优势。这个痛苦的教训是基于这样的历史观察:(1)AI 研究者经常试图将知识构建到他们的代理中;(2)这在短期内总是有帮助的,并且对研究者个人来说是满意的;(3)但是从长远来看,它会趋于平稳,甚至抑制进一步的进展;(4)突破性的进展最终会通过一种基于搜索和学习来扩展计算的相反的方法来实现。这也是伊尔亚·苏茨克维的信念和坚持。 启蒙运动带来了理性思考,科学家一直都在用这种人类的逻辑对万事万物分类,于是我们有了学科的概念,大家各自总结各学科的规律。但进入 20 世纪,哲学家 维特根斯坦 提出了一个新的观点:这种按学科分类做“知识图谱”的方法根本不可能穷尽所有的知识,事物之间总有些相似性是模糊的、不明确的、难以用语言来形容的。这种用全部人类语言信息训练出来的大语言模型,用人类没法理解的权重信息连接起来,压缩成了它自己的世界观和知识系统,而且还有极强的泛化和能力涌现,微软在针对 GPT-4 早期版本的能力研究中(Sparks of AGI),就发现了许多惊人的涌现能力,比如它可以仅从文字的理解和描述感知颜色,还能画出独角兽的外形。 随着大语言模型的快速进化,我们会看到知识经济境况的转变,但这种知识将不需要人类,而是由机器通过 AI 来拥有和管理。AI 将重新定义软件,或者说 AGI 将重写软件,那些需要人类丰富经验和专属化服务的行业,提供的服务将更便宜,服务形式将更多样。欣顿教授在采访中被问到实现 AGI 还需要多长时间,他之前认为至少要 20~50 年,但在看到 GPT-4 的能力后,他觉得 5~10 年内就可以实现。 人类的智能助理
|